stage4day4section1-4
Section1:強化学習
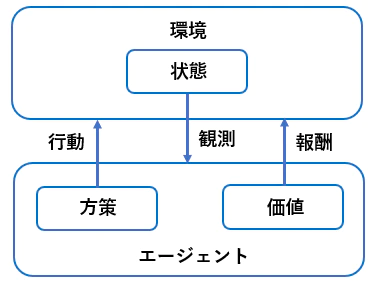
「エージェント」が「環境」の「状態」に応じてどのように「行動」すれば「報酬」が多くもらえるかを決める手法。
教師あり学習や教師なし学習と違い、
学習データなしに自身の試行錯誤のみで学習するのが特徴。
教師あり学習、教師無し学習 人間が成長する過程で自然に学んでいくプロセスと同じ
強化学習 人間が仕事で成果を出していくプロセスと同じ
⇒ AIを活用して何らかのタスクを実行し成果を期待しているので、この分野が注目されている。
・Q学習と関数近似法が理論的に重要 関数近似法が発明される前は、
「◯◯のときに□□を入れる」といったような膨大なリストを用意していた
・目標設定に当たるものが価値 (囲碁で言うと、勝敗が価値となる) - 状態価値関数 : 環境の状態が価値を変えるもの
(盤面の並びの状態だけ)
- 行動価値関数 : 状態と行動を基に価値が決まる
(盤面の状態の中でどういう一手を置くか)Q学習で使う。
・方策関数(囲碁で言うと、一手一手を考える) - 方策関数の結果に基づいて、エージェントは行動する
・方策勾配法 関数にできれば、NNにすることが出来き学習できる。 重みとしてθを取る
・NNの誤差関数を減らしていくことが学習に対して、
強化学習では期待収益増やしていくことが学習になる
Section2:AlphaGo
AlphaGoには
AlphaGo (Lee)とAlphaGo Zeroがある
■AlphaGo (Lee)の説明

李 世乭 Lee Sedolと戦ったプログラム
PolicyNet 方策関数
ValueNet 価値関数
2次元の場合はConvolutionするしかない(定石) 最後が1次元なら全結合するしかない
・いきなり強化学習をやってもうまくいかないので、最初は教師あり学習をやる
・次の一手を考えるのに、3ミリ秒かかるが、
何億回もやろうとすると結構なボリュームになる 何日とか掛かる
⇒ 精度は落ちるがスピード重視のものを使う ⇒ RollOutPolicy(NNではなく、線形の方策関数)1000倍速い ⇒ 3マイクロ秒/1手でできる
・教師あり学習において、RollOutPolicyを用いる
・3000万局面分の過去の人間vs人間の棋譜を学習させる(57%人間と同じ手を打つ)
・モンテカルロ木探索 現在、最も囲碁ソフトで使われている探索法 ⇒ 価値関数を学習させるときに用いる
■AlphaGo Zero 後発

スクラッチで作らている
強化学習のみで作成
*人間vs人間の棋譜を学習させていない
- ヒューリスティックな要素を排除
- PolicyNetとValueNetを統合(枝分かれ構造)
- Residual Netを導入
Residual Netにはショートカット構造が追加されている
- モンテカルロ木探索からRollOutシミュレーションをなくした
・ネットワークが深くなる ⇒ 潜在的に勾配消失(勾配爆発)問題が発生 ⇒ ショートカットを入れてやる ⇒ いろいろなパターンのネットワークを模擬できる(アンサンブル効果)
・E資格では、モデルの特徴が良く出題される
・現代の深層学習モデルでの根本的なネットワーク構造は、以下4つ - 畳み込み - プーリング - RNN - Attention
この4つは超重要!!
残りは上記4つの組み合わせが多い
論文書いた人が◯◯Netとか勝手に名前をつけている事が多い。
Section3:軽量化・高速化技術
モデル並列・データ並列・GPU
→高速化技術 モデルをいかに速く学習するか
量子化・蒸留・プルーニング
→軽量化技術 スマホとか簡易なデバイスでもモデルを動かせるようにしよう
・分散深層学習(最も大切な技術)
- ノートパソコンを複数台準備して、並列に学習させるイメージ。またはCPUの数を増やす。
- 毎年10倍の勢いで計算量が増えている
- コンピュータ(ワーカー)を増やす、CPUを増やす、GPU, TPUを使う、夜間の充電中のスマホを使う
・データ並列化
工夫の仕方
- 親モデルを子モデルにコピーして、
子モデルたちの勾配の平均値でパラメータを更新し、再度コピーする
(同期型 : 各ワーカーが計算が終わるのを待つ、
非同期型 : 各ワーカーはお互いの計算完了を待たない代わりに、
パラメータサーバーに順次結果を入れていく)
- 非同期型の方が処理は速いが、学習が不安定になりやすい
- 同期型か非同期型かは使い方による
(上記スマホの夜間利用のケースは非同期、自分たちでコントロールできるなら同期)
・モデル並列化
工夫の仕方
- 枝分かれ分割が主流
- 1台のPCで4つのGPUを接続して、みたいな使い方が多い
- データを集める際、ネットワーク経由だと遅い
- モデルが大きい ⇒ モデル並列化
- データが大きい ⇒ データ並列化
- 大きなモデルの方が、並列化の効果が高い
小さいモデルだと並列化効果が低い 例:人を沢山雇ってもタスクが小さいと不効率
(参照論文Google, 2016, Large Scale Distributed Deep Networks)
- 並列化による計算の効率化と分割したデータを集める時間のトレードオフ
- モデルの大きさはパラメータの数で示す
・GPUによる高速化
もともとはゲームや画像処理に特化したチップだったが、それを活用した
- CPU : 少数精鋭主義、優秀な人が少数で作業するイメージ
2秒/1画像
- GPU : 簡単な(行列計算)並列処理が得意、普通の人がいっぱいて作業するイメージ
0.5秒/1画像
- GPGPU
- CUDA(NVIDIA)
- Open CL(あまり使われていない)
・量子化 *軽量化で一番良く使う。量子コンピュータの話ではない。
重みの精度を下げることでメモリと演算処理の削減を行うこと。
通常のパラメータの64bit浮動小数点を
32bitなど下位の精度に落とす、など
- 計算は速く、省メモリ化が可能となるが精度は低下する
- 目盛を多く使う原因は重み(パラメータ)の情報(BERTだと数十億個)
- 2 Byte(半精度)、4 Byte(単精度)、16 Byte(倍精度)
- 64bitで量子化 ⇒ メモリが4GB、32bitで量子化 ⇒ メモリが2GB
- 前半5bitで整数の表現、後半11bitで小数の表現
- 大きなbit数で細かい数字まで表現できる
- 何ビットで表現するかが量子化の程度
- 16bitで150FLOPS程度
- 半精度でわりと十分
- 8 bitの小数は現在使われていない
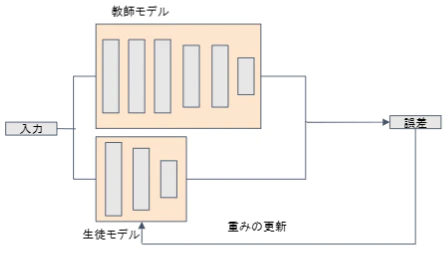
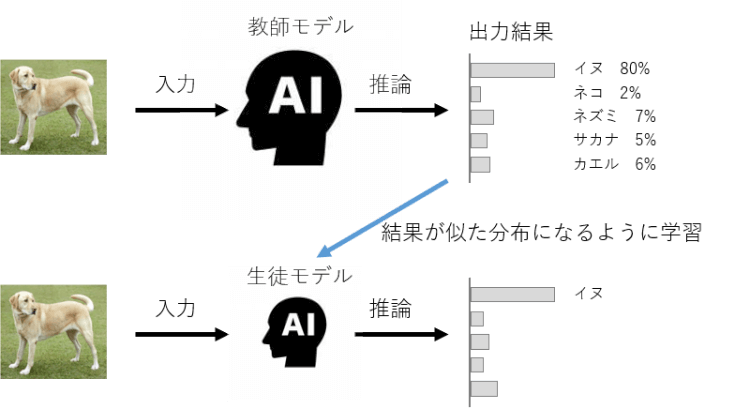
・蒸留
- 精度が高いモデルをまず作って、その後軽量なモデルを作る
- 教師モデル(学習済み)と生徒モデル
組み込み系のAI装置に活用されている
例)顔認識機能を持つスマホやサーマルカメラ
・プルーニング
- 寄与の少ないニューロンを削減して、軽量化
- 重みが閾値以下のニューロンを削減し、再学習
- 意外と性能が変わらない
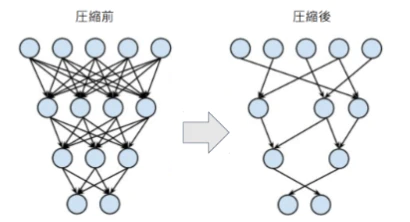
例)CaffeNetでパラメーターを9割減らしても精度があまり変わらない
Section4:応用モデル
ネットワークに関する問題(特徴)がよく出る
・画像認識モデルは2017年頃にほぼ完成していて、実用化されている その後は軽くて精度の良いものが研究されている
■MobileNet 先駆けとなった画像認識 最新版は第3世代
- 一般的な畳み込みレイヤーでの計算量が多いため、削減したい (計算量H x W x K x K x C x M)
ここで工夫が2つ
工夫1 - Depthwise Convolution > フィルタ数は1に固定 > 1つのチャンネルに対して、1枚のフィルタで畳み込みを実施 (計算量H x W x K x K x C x 1)
工夫2 - Pointwise Convolution > カーネルサイズを1 x 1に固定して、複数のフィルタで畳み込みを実施 (計算量H x W x 1 x 1 x C x M)
もともと
H x W x K x K x C x M 必要だった計算が
(H x W x K x K x C x 1) +(H x W x 1 x 1 x C x M) で同程度が期待できる。
つまり
に計算量を圧縮できる。
確認テスト

答え
(い)H x W x K x K x C x 1 Depthwise Convolution
(う)H x W x 1 x 1 x C x M Pointwise Convolution
■DenseNet - 画像認識のモデル - Denseブロックが特徴 > Batch正規化 > Relu > 3 x 3の畳み込み - 1層通過するごとにkずつチャンネルが増えていく (k : ネットワークのGrowth Rate) - チャンネル数が増え過ぎないようにTransitiion Layerがある
- ResNetのSkip Connectionとの違い
> ResNetは前の層から結合に対して、
>ハイパーパラメータ k : Growth Rate(成長率)
■Batch Normalizatiion - ミニバッチ単位で正規化する(平均が0、分散が1) > バッチサイズに影響を受ける > 理論的には順当な方法だが、実用ではあまり使いたくない、使えない >> 学習時のハードウェア性能によって、ミニバッチのサイズを変えざるを得ないため >> 再現性に欠ける
■Layer Normalization - 1枚毎の画像で正規化を行う。RGBであってもごちゃまぜにして1枚にする。 - TPUだと画像100枚ぐらいがミニバッチの上限 - CPUだと数十枚程度 - 統計的に正しいのはミニバッチだが、レイヤーでもうまくいったので実用されている - 入力データのスケール、重み行列のスケールやシフトに対してロバスト=堅牢 - 正規化はデータの特徴をそろえるイメージ
■Instance Normalization -各チャンネル独立に画像の縦横方向についてのみ平均・分散を取る -なぜか上手くいく
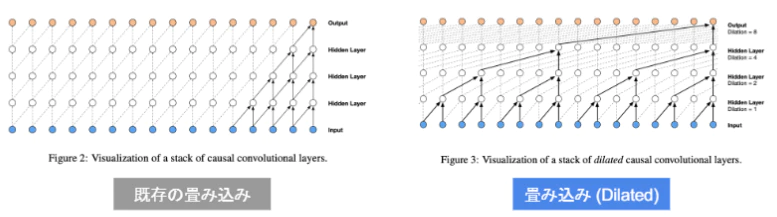
■WaveNet - 音声生成モデル(RNNではなくCNN) (時系列データに対して、畳み込みを適用) - とびとびに畳み込み処理をやっていける (幅広い範囲のデータを得ながら、出力を一定レベルに保てる) - Dilated casual convolution - パラメータに対する受容野が広い
利点
「層が深くなるにつれて畳み込むリンクを離す」
「受容野を簡単に増やすことができる」
・逆畳み込み演算 - 解像度を上げる時など 古いビデオを4kにする時など
確認テスト

